

Test to learn, not to win
If you have found this article you are probably already aware of the massive benefits to experimentation and why it is so important. (If this all sounds new, take a look at our article on how to kickstart your experimentation programme).
A lot of the emphasis on testing is placed at the start of the experimentation cycle; figuring out what your hypothesis is, what variations you run to maximise learning and what your primary metric should be. But what happens when your test is completed? How should you strategically approach this? Well the first thing is to evaluate your experiment and then take action, which normally comes in the form of an iteration. No matter the results provided by the experiment, there is always an opportunity to iterate.
But, what is iterative testing?
Whether you have uncovered a positive, or negative impact from your experiment, all experiments should be uncovering new user behaviour and insights, that we may not have known before. These learnings may indicate that there is a better experience for users, which is where iterations come into play.
Iterative testing in experimentation refers to making incremental changes or updates to a site or page based on insights (e.g. test results) from previous changes and testing them against predefined baseline metrics.
Why do we iterate?
Very often we find that businesses bounce from one hypothesis to the next, especially if the results of an experiment are not as expected.
The most important lesson you can learn as an experimenter is that you will never get it right the first time. The above is especially true as in order to establish causation; it is best practice not to change too many variables at once. Doing this makes it difficult for us to isolate changes and infer learnings. Therefore, an iterative process allows us to run several experiments or alternative routes to improve the same customer problem using the same hypothesis. We test different iterations of what worked well and what didn’t, to gain even more learnings and hopefully in the future -a winning experience that positively impacts our customers’ experience.
Declaring the outcome of our experiments: what to expect
Like with most experiments, you can usually expect one of three conclusions; winning, losing or an inconclusive result. In A/B/n testing, this is what they mean:
Winning
At least one of the experiment’s variations produces a statistically significant positive uplift against the control for the primary metric (the experiment’s measure of success; more info on defining this in our article here), but potentially for other secondary and monitoring metrics too.
Losing
Some or all the experiment’s variations produce a statistically significant negative uplift against the control for your primary metric, as well as potentially other business and monitoring metrics too.
Inconclusive
When the performance of all variations are flat and showing no statistically significant results for your primary metric, as well as your other included metrics.
Iterating on winning experiments
Great news! Something you have tested has proven to have a positive impact on your customer experience and has validated our hypothesis. Now what?
Firstly, we can get this winning experience safely implemented to everyone. Now we have actionable learnings from this experiment, we can iterate with the new experience being the control, meaning we are measuring the incremental impact of our iteration.
There could be several ways to take action depending on what the customer problem was and what was tested.
Let’s imagine your customers are not engaging with the filters on the product listing pages of your site. Your experiment hypothesis was geared around increasing prominence and you ran three variations to improve the prominence of filters on these pages.
“By increasing the prominence of filters on PLPs we expect to see an increase in users engaging with filter options to find their desired product, which in turn will have a positive impact on add to bag rate (primary metric: clicks on add to bag), conversion rate and overall revenue” – Creative CX hypothesis
All three variations produced a significant positive uplift on the primary metric (user engagement with the add to bag button) compared to the control.
Variation 1 was the highest contrast where filter options were added to the side column and made sticky as the user scrolls through the PLP. Since this produced the biggest uplift across key metrics, it suggests that increasing the prominence of filters by making them visible throughout the PLP browsing journey, had the best impact. This is a great basis for expansion!
This result indicates our hypothesis has been validated, providing support for the customer problem that we set out to solve in the first place. Based on this initial success, we may want to test further improvements, making changes we didn’t in the first experiment to isolate the changes. For this example, this could be simply adding filter options to the side column but not making them sticky this time.
In addition, we may have gathered learnings/insights from the monitoring metrics that we were unaware of before which may impact the execution we propose/test.
Iterating on losing experiments
Surprisingly, there are still many people across the industry that view losing tests as a bad thing. Embracing our failures is one of the key principles of embedding a culture of experimentation as with losing tests, comes a wealth of insight into what our users don’t like! There is a lot to be learned from a losing test and iterating from it is a way to validate our learnings through another iteration.
Taking our filters test example again, say we increased the prominence of filters and saw a positive impact on our primary metric (clicks on add to bag), but conversion rate significantly decreased which in turn had a negative impact on revenue. Just like a successful test, you must ask the question, “Why?” This is an example of a learning that has uncovered a different customer problem later in the visitors journey.
If your results are statistically significant, even though they are negative, you have still shown an ability to impact your visitors’ behavior with your experiment. You can now iterate on this to understand how this behaviour can be impacted in positive ways. In this example, the test is having a negative impact later down the shopping journey at the basket or checkout stage. This potentially uncovers a customer problem at the basket or checkout which may not have been looked at before, such as improved product description on PDPs. This is why iterations are incredibly powerful to uncover further learning and testing opportunities.
However, if you have iterated on this and are still finding there is still a negative impact, it’s okay to move on! Sometimes there may be an issue with the hypothesis, execution or data.
Iterating on inconclusive experiments
I think it’s fair to say that inconclusive tests are the most frustrating type of experiment result. You have the qualitative and quantitative data supporting your hypothesis, yet it’s flat across the board.
There’s a question of whether the test has been running for enough time; but if your test has run past the calculated test duration you should consider declaring the test inconclusive. This is especially true if you’ve exceeded the number of visitors you expected to see the experiment and the number of visitors remaining suggests you won’t reach significance anytime soon (>100,000 visitors remaining – yikes!).
While it can be difficult to pinpoint why you are seeing this result, often signs point towards you needing to be bolder with your variations!
Kyle Rush, former Head of Optimization at Optimizely says “Err on the side of testing the extreme version of your hypothesis. Subtle changes don’t usually reach significance as quickly as bigger changes. For the A/B test you want to know if your hypothesis is correct. Once you know that, you can fine tune the implementation of the hypothesis.”
Going back to our filters test as an example, perhaps the changes made across the variation went completely unnoticed by your visitors. More impactful changes, such as making the filter options larger and open by default will provide you with clearer insight into your visitors’ preferences when they are narrowing down product on PLPs, yielding stronger learnings for the next round of tests.
How to know when to call it a day?
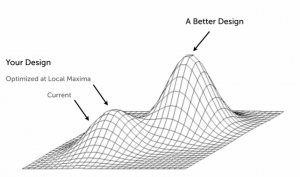
There comes a point where you have iterated from results and there is still no change. This could well be because these changes don’t address visitors’ actual issues, further gains are virtually non-existent or there isn’t an issue there in the first place. This could mean you have hit a local maximum as illustrated in the below diagram. In other words, this is where you have hit your peak of tests surrounding your hypothesis. This is also true when you have had consistent losing tests under the same hypothesis, this could indicate that the customer problem is not as accurate or great as we thought. This is the time to look at your hypothesis from a different angle or pivot your efforts to other areas of the site that can be improved.
Pitfalls of iterative testing – what to look out for!
Like most things, there are also some downsides to iterative testing that you should be aware of – so to avoid the traps!
Creates tunnel vision
When focusing on the one specific hypothesis each iteration, and looking at the same sorts of impact each time you can find yourself losing sight of the bigger picture, and by that I mean the full user journey. A way to avoid this is to regularly reflect on why you are testing this to start with:
- What is the exit intent of your customers – e.g what stopped them from purchasing/signing up?
- Post-purchase – what encouraged your customers to buy or sign up?
- How well does your site’s flow reflect the product or service you are offering?
There are limitations to isolated change tests too
Earlier, I touched on how important it is to isolate the changes to really understand the impact of each. When testing things all at once, it’s a challenge to understand which of the individual changes impacted user behaviour. However, depending on how subtle the change is, an isolated change test might require a pretty large test sample size or a longer test duration. Sometimes, some ideas are best run together more as a theme to the full user journey. You can then use funnel-step tracking to understand the impact.
Conclusion
As you have reached the end of this article, you can see there is a lot to be said about iterative testing. There is an important lesson in understanding that our experiments are very unlikely to be a ‘one hit wonder’ where we solve the customer problem entirely in a single test, and it’s the iterations that really allow us to unlock the fuller picture. In most cases, a better alternative is out there and we should be optimising towards it continuously.
To find out more about how best to run iterative experiments, feel free to reach out to us on LinkedIn or get in touch.

